Алгоритм, основанный на состоянии линии для сети
Как уже отмечалось, алгоритм, основанный на состоянии линий (Line State, LS), знает стоимость всех линий, то есть все эти данные можно подать на вход LS-алго-ритма. На практике, чтобы собрать эту информацию, каждый узел путем широковещательной рассылки отправляет свой идентификатор и стоимости всех присоединенных к нему линий всем остальным маршрутизаторам сети. Чтобы выполнить эту операцию, узлам не нужно знать идентификаторы всех остальных узлов сети. Узел должен лишь знать идентификаторы своих ближайших соседей, а также стоимости линий, соединяющих его с ними. О топологии остальной сети ему станет известно, когда он получит широковещательные пакеты с информацией о состоянии линий от других узлов. (В главе 5 мы узнаем, как маршрутизатор узнает идентификаторы своих ближайших соседей.) В результате всех этих широковещательных рассылок все узлы сети получают идентичное и полное представление о сети. Затем каждый узел может запустить алгоритм, основанный на состояниях линий, и вычислить пути к каждому из узлов.
Ниже мы рассмотрим пример алгоритма, основанный на состояниях линий, на примере алгоритма Дейкстры, названного по имени его создателя. Близко связан с ним алгоритм Прима. Алгоритм Дейкстры вычисляет путь с наименьшей стоимостью от одного узла (источника, который мы будем называть узлом Л) до всех остальных узлов сети. Алгоритм Дейкстры является итерационным и после k итераций он определяет пути с наименьшей стоимостью до k узлов-адресатов, и среди путей с наименьшей стоимостью до всех узлов-адресатов у этих k путей будут k наименьших стоимостей. Определим систему обозначений:
□ c(i,j) — стоимость линии от узла г до узла/ Если узлы i и j не соединены напрямую, тогда c(i,j) = ∞. Чтобы упростить нашу систему обозначений и примеры, мы будем предполагать, что c(i,j) = c(j, i). Однако следует отметить, что данный алгоритм будет работать и в случае, когда стоимости c(i,j) и c(j, i) не равны.
□ D(v) — стоимость пути от узла-источника до узла-адресата v, у которого на данный момент (на текущей итерации алгоритма) стоимость минимальна.
□ p(v) — предыдущий узел (соседний с узлом v) на текущем пути с наименьшей стоимостью от источника до узла v.
□ N — множество узлов, для которых на данной итерации известны пути с наименьшей стоимостью.
Алгоритм, основанный на состоянии линий, состоит из этапа инициализации, за которым следует цикл. Количество итераций этого цикла равно числу узлов в сети. По завершении алгоритм вычислит кратчайший путь от узла-источника (А) до всех остальных узлов сети.
Листинг 4.1. Алгоритм, основанный на состоянии линий для узла-источника А
1 инициализация:
2 N = {А}
3 для всех узлов v
4 если v смежный с А
5 тогда D(v) = c(A.v)
6 иначе D(v) = ∞
8 цикл
9 найти w, не входящий в N. такой что D(w) минимальна
10 добавить w к N
11 обновить D(v) для всех v. смежных с w и не входящих в N:
12 D(v) = min(D(v). D(w) + c(w.v))
13 /* новая стоимость пути к v равна старой стоимости к v или стоимости
14 известного кратчайшего пути к w плюс стоимость пути от w к v */
15 по всем узлам в N
В качестве примера рассмотрим сеть, показанную на рис. 4.4, и найдем пути с минимальной стоимостью от узла А до всех возможных адресатов. В табл. 4.2 показаны поэтапные результаты работы алгоритма. В каждой строке таблицы приведены значения переменных алгоритма в конце очередной итерации.

Рассмотрим подробно несколько первых шагов.
1. На шаге инициализации текущие наименьшие стоимости для путей от узла А до напрямую соединенных с ним соседних узлов В, С и D равны 2, 5 и 1 соответственно. Обратите, в частности, внимание, что стоимость пути до узла С установлена равной 5 (хотя вскоре мы увидим, что существует путь с меньшей стоимостью), так как этой величине равна стоимость прямой (один ретрансляционный участок) линии от узла А до узла С. Стоимости путей до узлов Ей Fустанавливаются равными бесконечности, так как эти узлы не связаны напрямую с узлом А.
2. На первой итерации из узлов, не входящих в множество N, мы выбираем узел с наименьшим по стоимости путем от узла А. Это узел D со стоимостью пути 1. Таким образом, узел D добавляется к множеству N. Затем выполняется строка 12 алгоритма, чтобы вычислить новое значение D(v) для всех узлов v и получить результаты, показанные во второй строке (шаг 1) табл. 4.2. Стоимость пути к узлу В не изменилась. Стоимость пути к узлу С (которая вначале была равна 5) через узел D оказалась равной 4. Таким образом, выбирается этот путь, имеющий наименьшую стоимость, а для узла С указывается, что путь с наименьшей стоимостью к нему проходит через узел D. Аналогично вычисляется стоимость пути до узла Е (через узел D), равная 2, что отражается в таблице.
3. На второй итерации следующими узлами с путями минимальной стоимости (равной 2) оказываются узлы В и Е. Мы произвольным образом выбираем из двух равноудаленных узлов один (узел Е) и добавляем его в набор N Теперь множество содержит узлы A,DhE. Стоимости путей до остальных узлов, еще не вошедших в множество N, то есть узлов В, Си F, вычисляются заново в строке 12 алгоритма. Результаты этих вычислений показаны в строке 3 табл. 4.2.
4. И т. д.
Когда LS-алгоритм завершает свою работу, для каждого узла мы узнаем узел-предшественник, через который проходит путь с наименьшей стоимостью к данному узлу. Для каждого узла-предшественника мы также знаем узел-предшественник и т. д. Таким образом, мы можем по этой информации построить полный путь от источника до любого адресата, а также сформировать таблицу маршрутизации для узла-источника.
Какова вычислительная сложность этого алгоритма? То есть сколько потребуется произвести вычислений в худшем случае, чтобы найти пути с наименьшей стоимостью от источника до всех п адресатов? На первой итерации мы должны просмотреть все п узлов, чтобы найти узел w, не принадлежащий множеству N, стоимость пути до которого минимальна. На второй итерации мы должны просмотреть гг — 1 узлов, чтобы найти узел с путем наименьшей стоимости. На третьей итерации нам придется просмотреть п — 2 узлов, и т. д. Всего нам придется просмотреть п(п + 1)/2 узлов. Таким образом, количество вычислений в алгоритме, основанном на состоянии линий, растет пропорционально квадрату узлов сети: 0(п2). Существует и более сложный вариант этого алгоритма, в котором используется структура данных, называемая «кучей» (heap). Данному алгоритму для нахождения минимума в строке 9 требуется время, пропорциональное логарифму от числа рассматриваемых узлов, что снижает суммарное время выполнения алгоритма.
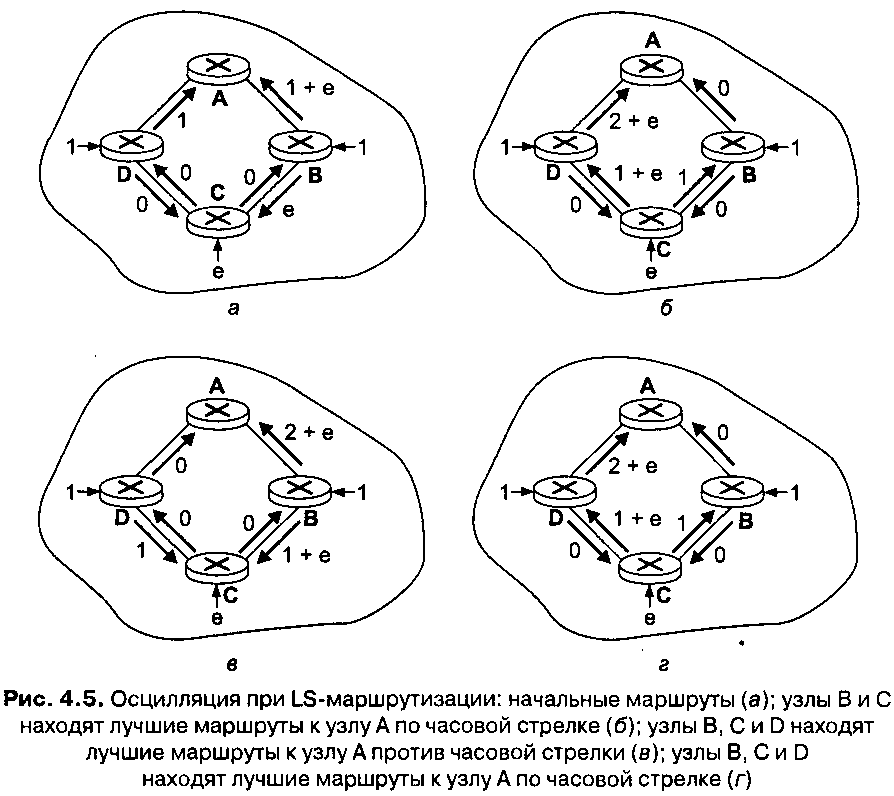
Прежде чем завершить наше обсуждение LS-алгоритма, рассмотрим патологическую ситуацию, которая может возникнуть. На рис. 4.5 показана схема простой сети, в которой стоимость линии пропорциональна текущей нагрузке на линию, например, оцениваемой по испытываемой задержке. В данном примере стоимости линий несимметричны, то есть стоимость линии с(Л, В) равна с(В, Л) только в том случае, если нагрузка на линию ЛВ одинакова в обоих направлениях. В данном примере узел D передает единичную порцию трафика узлу Л, узел В также посылает единичную порцию трафика узлу Л, а узел С посылает узлу Л порцию трафика объема е. Начальная схема маршрутизации, в кбторой стоимости линий соответствуют количеству трафика, показана на рис. 4.5, а.
Когда в очередной раз запускается LS-алгоритм, узел С определяет (на основании стоимостей линий, показанных на рис. 4.5, а), что путь к узлу Л по часовой стрелке обладает стоимостью 1, тогда как стоимость пути к этому же узлу против часовой стрелки (которым он пользовался до сих пбр) равна 1 + е. Таким образом, путь наименьшей стоимости от узла С к узлу Л теперь имеет направление по часовой стрелке. Аналогично, узел В определяет, что его новый путь к узлу Л с наименьшей стоимостью также направлен по часовой стрелке, в результате чего вычисляются новые стоимости путей, показанные на рис. 4.5, б. При следующем запуске LS-алгоритма узлы В, С и D обнаруживают путь нулевой стоимости к узлу Л в направлении против часовой стрелки, поэтому все узлы направляют свой трафик против часовой стрелки. В следующий раз эти же узлы обнаруживают, что дешевле направлять трафик по часовой стрелке, так как в этом направлении никакого трафика нет.
Что можно предпринять, чтобы предотвратить подобный колебательный процесс? Осцилляция может возникнуть в любом алгоритме (не только в LS-алгоритме), использующем уровень загруженности линий или задержку в линиях в качестве параметра определения стоимости линий. Один из методов решения данной проблемы заключается в том, чтобы стоимость линий не зависела от текущего объема трафика, проходящего по ним. Однако такое решение является неприемлемым, так как наша цель состоит в том, чтобы алгоритм мог пускать потоки данных в обход сильно загруженных линий (например, с высокой задержкой). Другое возможное решение могло бы гарантировать, что не все маршрутизаторы запустят LS-ал-горитм в одно и то же время. Это решение кажется более разумным, так как есть надежда, что даже если маршрутизаторы запускают LS-алгоритм с одной и той же периодичностью, исполняемые экземпляры алгоритма не будут одинаковыми на каждом узле. Исследователи недавно отметили, что маршрутизаторы Интернета могут самосинхронизироваться. То есть даже если изначально они выполняют один и тот же алгоритм с одним и тем же периодом, но с разной фазой, со временем алгоритмы на разных узлах синхронизируются и остаются синхронными. Один из способов избежать синхронизации состоит в том, чтобы намеренно сделать случайными интервалы времени между запусками алгоритма на каждом узле.
Итак, мы обсудили алгоритм маршрутизации, основанный на состоянии линий. Рассмотрим теперь другой важный алгоритм маршрутизации, применяемый сегодня на практике, — алгоритм дистанционно-векторной маршрутизации.