Поток запросов
В бесплатном приложении для совместного использования файлов Gnutella задействована полностью распределенная модель распределения ресурсов. В этой модели одноранговые системы самоорганизуются в оверлейную сеть. В отличие от оверлейной сети, описанной выше, сеть приложения Gnutella имеет «плоскую», неструктурированную топологию. Все пользователи равны между собой, поскольку иерархическая структура в сети отсутствует. Рисунок 2.32 иллюстрирует графическое представление описываемой топологии. Как и в предыдущей модели, присоединение новой системы происходит с помощью узла начальной загрузки, выдающего IP-адреса одного или нескольких существующих пользователей сети. Каждая система располагает сведениями только о своих соседях, то есть системах, с которыми у нее имеется логическая связь. Для поддержки подобной оверлейной сети требуется сложный протокол, учитывающий постоянные динамические изменения структуры сети, связанные с подключениями и отключениями пользователей.
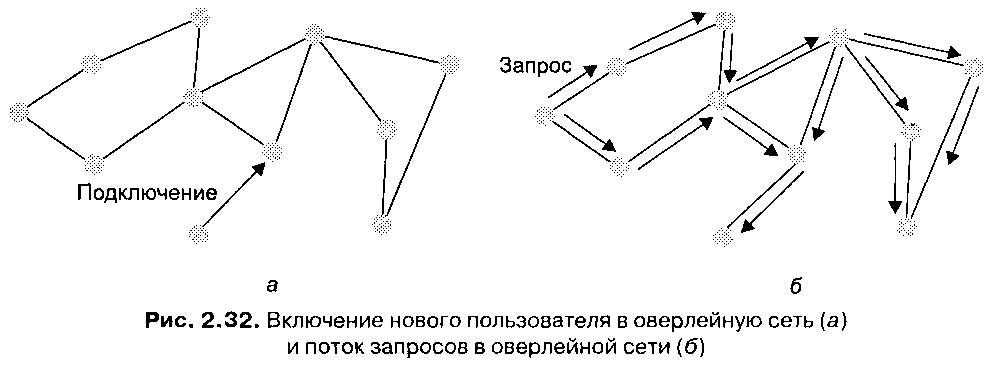
Для поиска объектов в приложении Gnutella не используются каталоги (ни централизованные, ни децентрализованные); вместо них применяется поток запросов, суть которого заключается в следующем. Когда некоторый пользователь, например Алиса, желает получить объект, приложение направляет запросы на получение этого объекта соседним системам. Последние, в свою очередь, направляют запросы своим соседям (кроме Алисы), и эта процедура продолжается до тех пор, пока запросы не будут переданы всем системам сети. При наличии объекта система отправляет соответствующий ответ системе, отправившей запрос.
Информационная модель, используемая приложением Gnutella, обладает рядом несомненных достоинств. Прежде всего, следует отметить реальную одноранговость (равноправие) всех систем, приводящую к равномерному распределению обязанностей между ними. Кроме того, ни одна из систем не хранит информацию, связывающую ресурсы с IP-адресами. Отсутствие базы данных (централизованной или распределенной) значительно упрощает модель системы.
Вместе с тем приложение Gnutella часто критикуется за невозможность масштабирования. При использовании модели в том виде, в котором мы ее описали, любой запрос распространяется по всей сети. Это приводит к значительному трафику запросов, которые должны обрабатываться каждой системой. Разработчики Gnutella предусмотрели решение этой проблемы, ограничив область распространения запросов определенным числом систем. Запрос включает в себя специальное поле, содержащее счетчик узлов, через которые прошел запрос. При создании запроса значение счетчика устанавливается равным области распространения и при прохождении каждой системой декрементируется. Если система получает запрос с нулевым значением счетчика, дальнейшая пересылка запроса прекращается. Такой подход позволяет сократить объем трафика запросов, однако повышает вероятность того, что список пользователей, располагающих требуемым объектом, окажется неполным.
Как и в схеме с децентрализованным каталогом, система Gnutella вынуждена поддерживать оверлейную сеть. Несмотря на то что данная задача является весьма непростой, на практике ее решение вполне достижимо. Для присоединения к сети новых систем используется один или несколько узлов начальной загрузки. На сегодняшний день задача построения одноранговой сети без узлов начальной загрузки не решена.
Как и упомянутые выше системы Napster и KaZaA/FastTrack, Gnutella пережила стремительный взлет популярности, приобретя миллионы новых пользователей за несколько месяцев функционирования. Бурное развитие одноранговых приложений, включая системы обмена сообщениями в реальном времени и совместного использования файлов, в очередной раз показало исключительную универсальность структуры Интернета, позволившую успешно функционировать на протяжении 25 лет после создания, поддерживая множество самых разных приложений. Разумеется, функционирование этих приложений невозможно без специальных средств обслуживания, куда входят системы передачи дейтаграмм с установлением и без установления соединения, системы адресации и именования (DNS), интерфейс сокетов и др. Поскольку приложения находятся на самом верхнем уровне стека протоколов Интернета, их разработка означает разработку нового программного обеспечения, предназначенного для взаимодействия оконечных систем с использованием парадигмы клиент/сервер.
Отметим, что далеко не все разработки в сфере Интернет-приложений являются столь же успешными, как системы обмена сообщениями в реальном времени и совместного использования файлов. Так, например, приложения, предназначенные для работы с потоковым мультимедиа и организации видеоконференций, до сих пор далеки от популярности. Вероятно, это можно объяснить недостаточной сетевой поддержкой (мы обсудим существующие средства поддержки в главе 6) либо негативным влиянием социально-экономических факторов.
Хорошо структурированная статья. Интересует, какая технология используется для поддержки такого потока запросов?
Мне кажется, что это может революционизировать обработку данных. Какие есть примеры реализации в реальных проектах?