Кодировки в C++
Всем рано или поздно приходится работать с различными кодировками. Заметив в коде своей команды различные, порой странные, подходы к решению этих проблем, пришлось провести разъяснительную беседу. Ниже поделюсь своим видением правильной работы с не-ASCII символами в коде. Буду рад конструктивной критике.
Принцип работы
Логика работы с различными кодировками в C++ проста и прозрачна. В общем виде она отражена в схеме. Программа работает в одной — своей внутренней кодировке, а правильно локализованные потоки отвечают за преобразование кодировки данных из внешнего кода во внутренний и обратно. Внутреннюю кодировку программы лучше всего зафиксировать раз и навсегда. Если программа работает с не-ASCII символами, то самый логичный выбор для внутренней кодировки — Юникод, причём использование UTF-8 и char для параметризации STL как правило неоправданно (хотя существуют ситуации, в которых это необходимо); более логично перейти на расширенные символы wchar_t и использовать UCS-2. За преобразование данных из внешней кодировки во внутреннюю отвечает фасет codecvt. Локализованные потоки сами вызовут соответствующие функции фасета при получении данных (о том кто такие фасеты я писал ранее).
Вышесказанное поясню комментированным примером, в котором прочитаем данные из cp1251 файла, покажем как boost::xpressive работает с юникодом и выведем кириллицу в cout в кодировке cp866 (консоль windows по умолчанию).
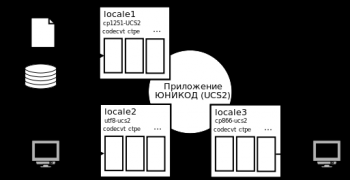
Кодировка исходников
Прежде чем приступить к рассмотрению примера, следует (на всякий случай) пару слов сказать о кодировке исходных текстов программы. Все свои исходники я держу в UTF-8 (если они содержат широкие строковые константы с не-ASCII символами, то в файлы добавляю BOM), что и всем советую. Современные компиляторы сами преобразуют «широкие» символы, помеченные в исходниках как L"" в UCS-2 (или UCS-4). Понятно, что правильное преобразование зависит от кодировки исходников. gcc по-умолчанию считает, что работает с UTF-8 текстом, чтобы его переубедить придётся специально указывать значение параметра -finput-charset. Компилятору от MS нужно немножечко помочь — добавить в UTF-8 файл BOM (Byte Order Mark). К сожалению у Borland C++ Compiler version 5.5 с UTF-8 проблемы.
Для тех, кто собрался кинуть в меня камень поясню два момента: первый — мне не удобно читать код с «unicode escape» типа:
std::wstring wstr(L"u0410u0411u0412u0413u0413");
второй — речь идёт не только об интерфейсе пользователя, поэтому вынести все широкие строковые константы в отдельный модуль и как-то с ними работать (наподобие gettext), не вариант.
Итак решено — исходники в UTF-8 с BOM. Если кто не знает, в vim BOM можно добавить к файлу с помощью команды «set bomb». Если BOM в файле уже есть vim его никуда не денет.
Пример работы с различными кодировками
Ну вот и подобрались к самому интересному. Как я и говорил, код простой и понятный. Маленькое замечание по стандартным потокам — по умолчанию фасеты для них не задействуются так как они синхронизированы с stdio для производительности. Следует указать sync_with_stdio(false).
#include
#include
#include
#include
#include
#include "codecvt_cp866.hpp"
#include "codecvt_cp1251.hpp"
#include "unicyr_ctype.hpp"
using namespace std;
using namespace boost::xpressive;
int main()
{
// Пусть имеется файл input.txt в кодировке cp1251, содержащий банальный
// "Привет, мир!"
ofstream ofile("input.txt", std::ios::binary);
ostreambuf_iterator writer(ofile);
writer = 0xCF; // П
++writer = 0xF0; // р
++writer = 0xE8; // и
++writer = 0xE2; // в
++writer = 0xE5; // е
++writer = 0xF2; // т
++writer = 0x2C; // ,
++writer = 0x20; //
++writer = 0xEC; // м
++writer = 0xE8; // и
++writer = 0xF0; // р
++writer = 0x21; // !
ofile.close();
// Читаем файл
wifstream ifile("input.txt");
// Локаль для ввода
locale cp1251(locale(""), new codecvt_cp1251);
ifile.imbue(cp1251);
wchar_t wstr[14];
ifile.getline(wstr, 13);
// Стандарт C++ предписывает синхронизировать cout, cin, cerr и
// clog, как и их расширенные варианты с stdio, поэтому поумолчанию
// для этих потоков фасет не будет задействован (во всяком случае при
// компиляции gcc, msvc 7 не особо придерживается стандартов). Следует
// сообщить ios, что мы не будем синхронизироваться с stdio.
ios_base::sync_with_stdio(false);
// Локаль для вывода
locale cp866(locale(""), new codecvt_cp866);
// Сообщаем потоку, что перед выводом необходимо выполнять
// преобразование
wcout.imbue(cp866);
// Локаль с правильным ctype
locale cyrr(locale(""), new unicyr_ctype);
wsregex_compiler xpr_compiler;
xpr_compiler.imbue(cyrr);
wsregex xpr = xpr_compiler.compile(L"МИР", regex_constants::icase);
wsmatch match;
if(regex_search(wstring(wstr), match, xpr))
wcout
Мой блог находят по следующим фразам